5.2 分析準備
本章では、変数間の関係を捉える回帰分析について、そのモデルの基礎と統計的推測に基づく解釈を説明する。回帰分析結果から得られる含意は、「予測」と「検証」の二つに大別することができる。その上で特に本書では、「検証」という側面、特に「研究上関心のある説明変数の係数の解釈」を重視する立場を取る。立場が異なれば、回帰分析において何を重視するかという観点も異なるため、注意してほしい。
なお本章では、3 章でも利用した MktRes_firmdata.xlsxという企業データを用いた分析を行う。次節に移る前に以下の要領でデータを読み込んでほしい。
本章では主に、firmdata における2019年のデータを抽出し、クロスセクショナルデータとして用いる。以下の様に全データから2019年の情報を抽出してほしい。
## ── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
## ✔ dplyr 1.1.4 ✔ readr 2.1.5
## ✔ forcats 1.0.0 ✔ stringr 1.5.1
## ✔ ggplot2 3.5.2 ✔ tibble 3.3.0
## ✔ lubridate 1.9.4 ✔ tidyr 1.3.1
## ✔ purrr 1.0.4
## ── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
## ✖ dplyr::filter() masks stats::filter()
## ✖ dplyr::lag() masks stats::lag()
## ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errorsデータを用いた分析を行う場合、取得したデータの記述統計や分布を確認する必要がある。本来であれば研究上重要な変数を対象にデータの特徴を整理するが、ここでは複数の変数の特徴を一括で整理、図示化する方法を提示する。この方法では、GGallyというパッケージのggpairs()という関数を用いるため、以下のようにパッケージをダウンロードしてほしい。
firmdata19 データセットから、例として四つの変数を抽出して、ggpairsを実行する。これにより、各変数のヒストグラム(密度形式)と、それぞれの変数間の相関係数と散布図が同図内で示されている。また、ggpairs()内の引数設定によって様々な図示形式を指定できるため、興味のある人は調べてみてほしい。
firmdata19 %>%
select(sales, mkexp, emp, operating_profit) %>%
GGally::ggpairs()+ labs(title = "ggpairs example")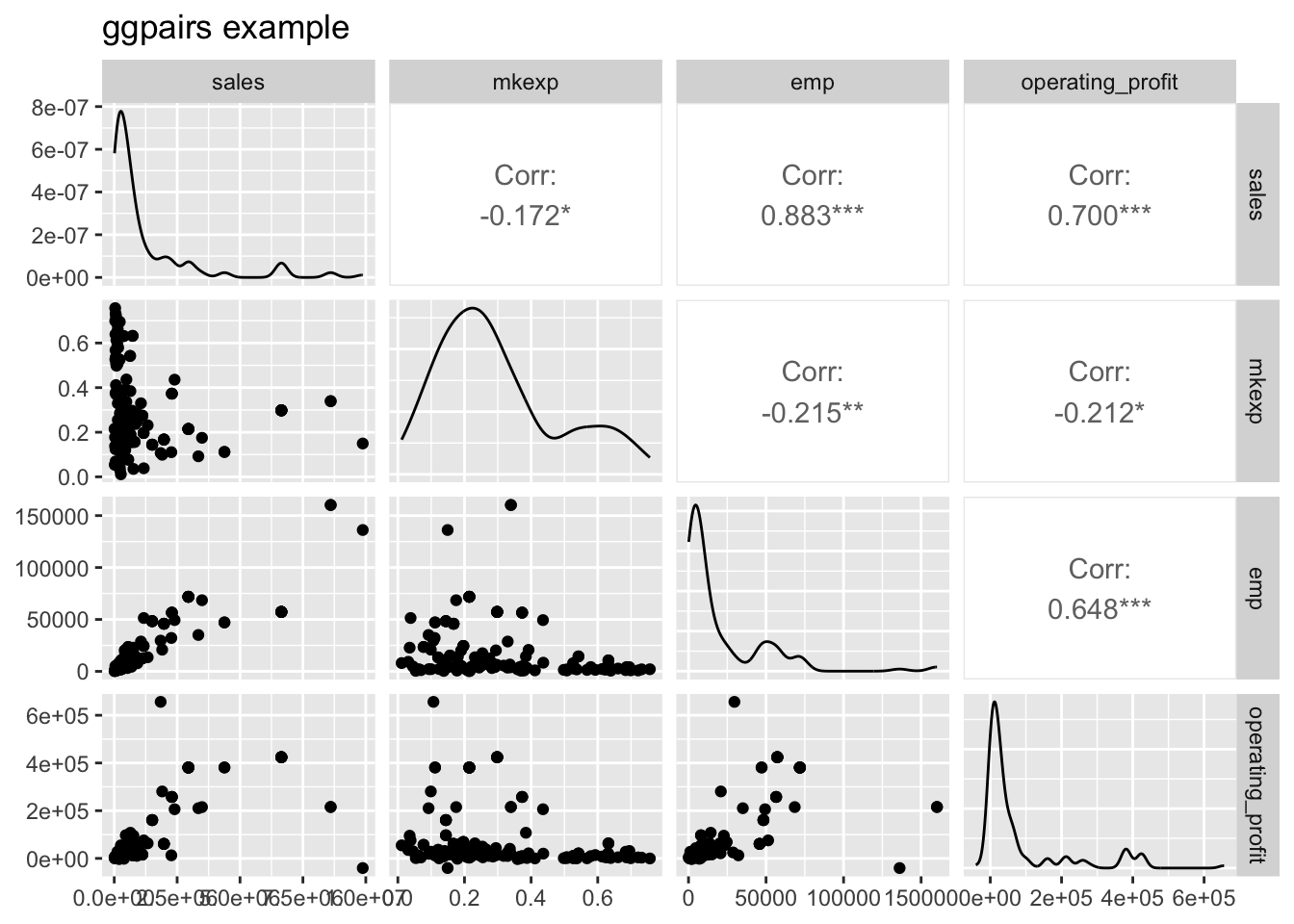
なお、記述統計については既出の summary()関数にデータフレームを指定することで、データセット全体の記述統計を出力する。ここでは例として先程と同じ変数の記述統計を以下のように出力してみる。
ds1 <- firmdata19 %>%
select(sales, mkexp, emp, operating_profit) %>%
summary()
knitr::kable(ds1, align = "cccc")| sales | mkexp | emp | operating_profit | |
|---|---|---|---|---|
| Min. : 11333 | Min. :0.01137 | Min. : 163 | Min. :-40469 | |
| 1st Qu.: 183525 | 1st Qu.:0.16714 | 1st Qu.: 3454 | 1st Qu.: 7743 | |
| Median : 464450 | Median :0.25448 | Median : 7826 | Median : 23904 | |
| Mean :1199403 | Mean :0.29868 | Mean : 20249 | Mean : 81088 | |
| 3rd Qu.:1164243 | 3rd Qu.:0.37506 | 3rd Qu.: 24464 | 3rd Qu.: 63068 | |
| Max. :9878866 | Max. :0.75650 | Max. :160227 | Max. :656163 |