Chapter 8 回帰分析
本章では、変数間の関係を捉える回帰分析について、そのモデルの基礎と統計的推測に基づく解釈を説明する。回帰分析結果から得られる含意は、「予測」と「検証」の二つに大別することができる。その上で特に本書では、「検証」という側面、特に「研究上関心のある説明変数の係数の解釈」を重視する立場を取る。立場が異なれば、回帰分析上何を重視するかという観点も異なるため、特に回帰分析による予測に関心のある読者においては別の図書を参照してほしい。
なお、本節では、MktRes_firmdata.xlsxという企業データを用いた分析を行う。次節に移る前に以下の要領でデータを読み込んでほしい。
このデータは、小売・サービス分野の企業約160社(企業数は年によって異なる)に関する2010年から2019年までの財務データである(計1440件)。このデータは、日本生産性本部における顧客満足度調査の対象になっている企業リストを作成し、その企業の中から金融領域の企業や、データを入手できなかった一部の企業を教育的意図から排除したものである。したがって、日本の小売・サービス分野において全国的に知名度のある代表的な企業の財務データ(の一部)だと考えられる。
なお、本データには以下の変数が含まれており、データ内の単位は従業員数(人)を除き百万円である。
- fyear: 決算年
- legalname: 企業名
- ind_en: 日経業種名(英文)
- parent:親会社名(もしあれば)
- fiscal_month: 決算月
- current_liability: 流動負債
- ltloans: 長期借入金
- total_liability: 負債合計
- current_assets: 流動資産
- ppent: 有形固定資産
- total_assets: 資産合計
- net_assets_per_capital: 純資産合計/資本合計
- sales: 売上高
- sga: 販売費及び一般管理費
- operating_profit: 営業利益
- net_profit: 当期純利益
- pnet_profit: 親会社株主に帰属する当期純利益(連結)/当期利益(単独)
- re: 利益剰余金
- adv: 広告・宣伝費
- labor_cost: 人件費
- rd: 研究開発費
- other_sg: その他販売費及び一般管理費
- emp: 期末従業員数
- temp: 平均臨時従業員数
- tempratio: temp/(emp+temp)
- indgrowth: 産業成長率
- adint: 広告集中率(adv/sales)
- rdint: 研究集中率(rd/sales)
- mkexp: (sga - rd) / sales
- op: operating_profit / sales
- roa: pnet_profit / total_assets
本データセットは、複数年にわたる複数サンプルからのデータであり、一般的にこのような構造のデータをパネルデータという。パネルデータの分析は本講義の範囲外なので、本章では主に、2019年のデータ抽出し、クロスセクショナルデータとして用いる。以下の様に全データから2019年の情報を抽出してほしい。
データを用いた分析を行う場合、取得したデータの記述統計や分布を確認する必要がある。本来であれば研究上重要な変数を対象にデータの特徴を整理するが、ここでは複数の変数の特徴を一括で整理、図示化する方法を提示する。この方法では、GGallyというパッケージのggpairs()という関数を用いるため、以下のようにパッケージをダウンロードしてほしい。
firmdata19 データセットから、例として四つの変数を抽出して、ggpairsを実行する。これにより、各変数のヒストグラム(密度形式)と、それぞれの変数間の相関係数と散布図が同図内で示されている。また、ggpairs()内の引数設定によって様々な図示形式を指定できるため、興味のある人は調べてみてほしい。
firmdata19 %>%
select(sales, mkexp, emp, operating_profit) %>%
GGally::ggpairs()+ labs(title = "ggpairs example")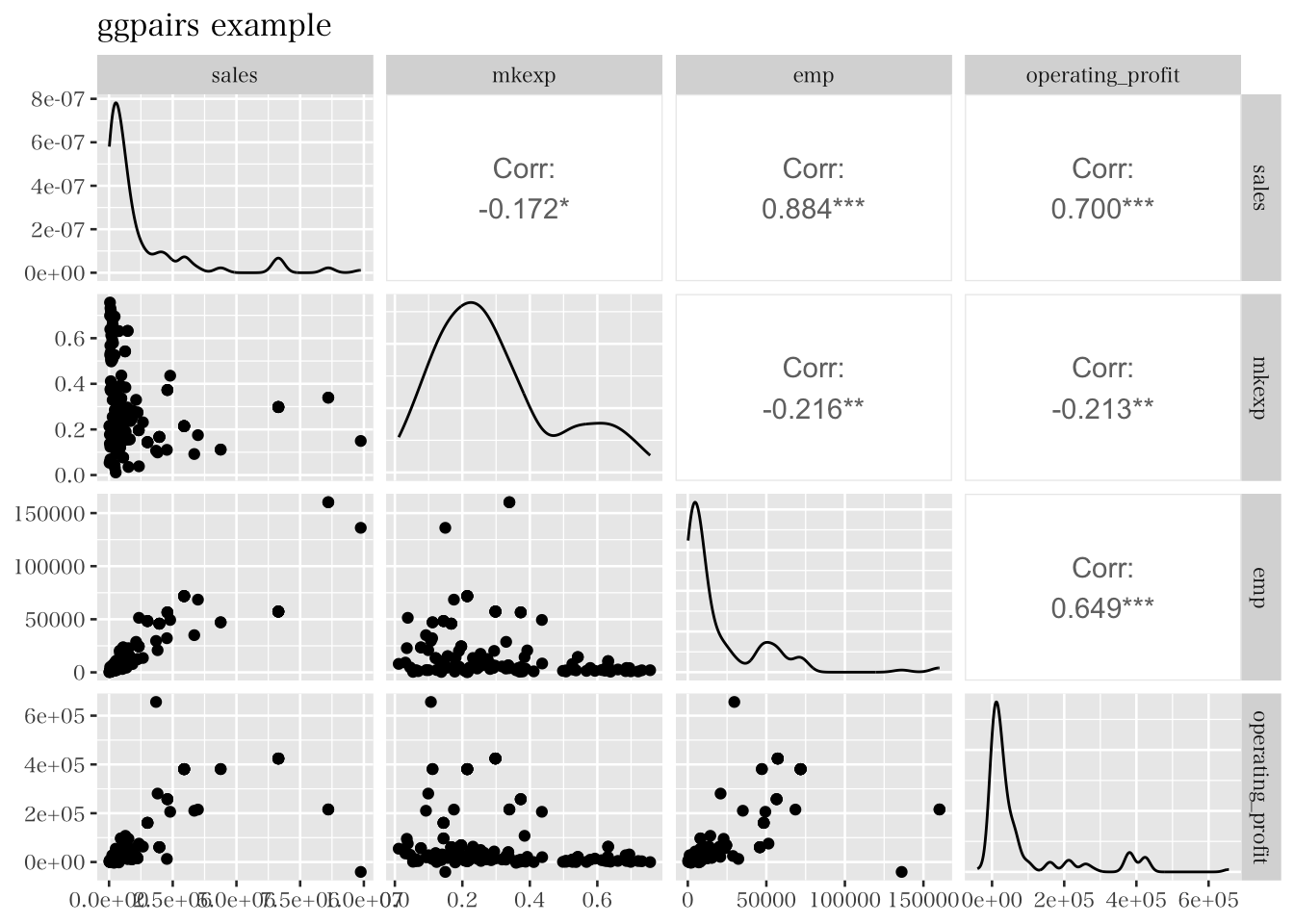
なお、記述統計については既出の summary()関数にデータフレームを指定することで、データセット全体の記述統計を出力する。ここでは例として先程と同じ変数の記述統計を以下のように出力してみる。
ds1 <- firmdata19 %>%
select(sales, mkexp, emp, operating_profit) %>%
summary()
knitr::kable(ds1, align = "cccc")| sales | mkexp | emp | operating_profit | |
|---|---|---|---|---|
| Min. : 11333 | Min. :0.01137 | Min. : 163 | Min. :-40469 | |
| 1st Qu.: 186830 | 1st Qu.:0.16714 | 1st Qu.: 3488 | 1st Qu.: 7788 | |
| Median : 464450 | Median :0.25508 | Median : 7825 | Median : 24824 | |
| Mean :1194513 | Mean :0.29894 | Mean : 20156 | Mean : 80811 | |
| 3rd Qu.:1164243 | 3rd Qu.:0.37438 | 3rd Qu.: 24464 | 3rd Qu.: 63026 | |
| Max. :9878866 | Max. :0.75650 | Max. :160227 | Max. :656163 |