11.2 因子分析概要
11.2.1 因子分析の概要とモデルの構造
本節では、因子分析の概要を説明する。因子分析とは観測された変数の背後に「潜在的」な共通因子 (common factor)が存在することを仮定し、その「潜在因子から観測変数への影響」の度合いを推定することで観測された変数同士の相関(まとまり)を説明しようとする方法である。因子分析は心理学分野で発展した手法であり、人々の心理的特徴(例えば、価格志向やコスモポリタニズム)を多面的に捉えることや、情報の複雑さを削減することができる。
因子分析には大きく分けて1つのアプローチが存在する。第1に、探索的因子分析である。これは、複数の観測変数間の相関関係から、その背後にいくつ潜在的な因子を導入すれば観測変数間の関係をうまく説明できるのかを探索的に調査・分析する方法である。第2に、確認的因子分析である。これは、先行研究などに基づき、因子の数と因子負荷量について仮説的な構造を想定し、その構造をデータに基づき検証する方法である。この手法は、共分散構造分析と呼ばれる分析手法を応用したものである。これら2つのうち本講義では、探索的因子分析に焦点を合わせる。
因子分析では、観測変数の値を規定するような、共通する潜在因子が存在すると考える。図11.3 は、3つの観測変数と1つの潜在因子との関係を表す因子モデルを図示したものである。因子分析では観測変数間の相関を捉えており、観測変数間に高い相関があるということは、その背後に共通する因子があると考える。図11.3 における \(f\) は潜在因子、 \(x_j~(j=1,2,3)\) は観測変数を表している。また、因子と変数の関連性は \(a_j\) という因子負荷量で表現され、 \(e_j\) は因子では説明できない変数のばらつきを表す独自因子と呼ばれる。図示化においては、一般的に観測変数は四角形、潜在因子と独自因子は円や楕円で表現される事が多い。
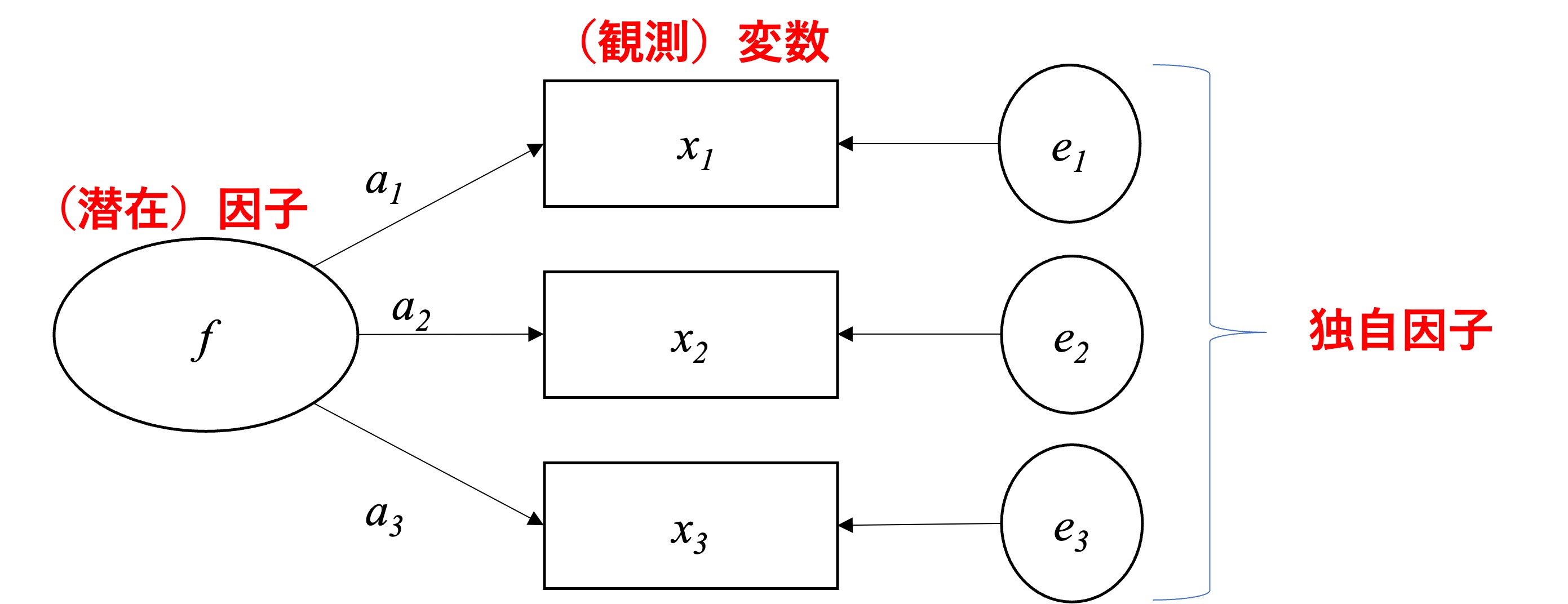
Figure 11.3: 因子分析モデル
図11.3のパス図は、以下のような式で表すことができる。
\[ x_{1i}=a_1f_i+e_{1i}\\ x_{2i}=a_2f_i+e_{2i}\\ x_{3i}=a_3f_i+e_{3i}, \] ただし、\(i\) は \(1,..,n\) の個人を指す。そのため、因子分析のモデルは、各観測変数それぞれを被説名変数とし、潜在因子を説明変数とした回帰モデルのような形で捉えることができる。このことからも、潜在因子が観測変数を規定しているという考えのもとモデルが構築されていることがうかがえる。因子分析においては、上記の式をもとに、因子負荷量を求める17のだが、ここで潜在因子を式に含めていることの問題が浮上する。説名変数として用いている潜在変数は、本来観察できないものであるため、単位や基準点が存在せず、式が変形可能になってしまい、因子負荷量についての解が定まらない(分寺、2022)。そこで、因子分析の実行においては以下のいずれかの制約をおく:
- 因子の分散が1、平均が0と仮定する。
- 1つ目の観測変数の因子負荷量を1に固定する。
このような仮定の下、因子負荷量を計算するのだが、因子負荷量の計算方法はいくつか存在する。詳細についてはぜひ分寺(2022)を参照してほしい。ここでは、分析後に算出されるいくつかの重要な指標について簡単に説明する。まずは、想定した因子モデルがどの程度うまく観測変数のばらつきを説明できているのかを表す共通性と独自性について説明する。 ここで、\(j\) 番目の観測変数(\(j=1,...,J\))に対応する以下のような因子モデルを考える。
\[ x_{ji}=a_jf_i+e_{ji} \] この時、\(\hat{x}_{ji}\) は \(x_{ji}\) の予測値、\(\hat{e}_{ji}\) は 残差とすると、以下のような式を得ることができる。
\[ x_{ij}=\hat{x}_{ji}+\hat{e}_{ji}=\hat{a}_jf+\hat{x}_{ji} \]
上記の式において説明変数に潜在因子が使われていることには注意が必要であるが、\(x\) の分散と予測値や残差との関係について、回帰分析の場合と同様に、以下のように捉えることができる。
\[ \sum_{i=1}^n(x_{ji}-\bar{x}_j)^2=\sum(\hat{x}_{ji}-\bar{x}_j)+\sum(x_{ji}-\hat{x}_{ji}) \]
この時、\(\sum(x_{ji}-\bar{x}_j)^2\) をSST(Total Sum of Squares)、\(\sum(\hat{x}_{ji}-\bar{x}_j)\) をSSE(Sum of Squares Explained)、\(\sum(x_{ji}-\hat{x}_{ji}\) をSSR(Residual Sum of Squares)と定義すると、以下のように変形できる。
\[ 1=\frac{SSE}{SST}+\frac{SSR}{SST} \] この時、右辺第一項は共通性(観測変数全体の変動のうち、因子で説明できる部分)、第二項は独自性(観測変数全体の変動のうち、因子で説明できない部分)と呼ばれる。
これまでの因子モデルにおいて \(a_j\)として示された因子負荷量は、因子がそれぞれの観測変数にどの程度影響を与えているかを表しており、因子負荷量が高い程、因子と観測変数の関連が強いことを示す。また、因子分析を実行すると、因子寄与率(分散比率)が算出される。これは、観測項目全体の分散を因子によってどの程度説明しているかを示している。
11.2.2 2因子モデル
ここまでの説明では、1つの因子を想定した1因子モデルを紹介したが、因子分析は複数の因子を想定したモデルも採用できる。この場合も、基本的には1因子モデルと同じように計算が可能だが、複数因子モデルにおいては、(1)軸の回転と、(2)因子数の決定、という2点について追加的に考える必要が出てくる。複数因子モデルでは、因子\(\times\)因子負荷量の解の座標の取り方が一意定まらないという性質を持っている。例えば、観測変数を \(J\)個、潜在因子を2個含むモデルを行列表記を用いて以下のように示す。
\[ \boldsymbol{x}=\boldsymbol{Af}+\boldsymbol{e} \]
ここで、上記の式は、任意の(\(p\times p\))の正則行列(逆行列が存在する正方行列)\(\boldsymbol{T}\)を用いて以下のように示すこともできる。
\[ \boldsymbol{x}=\boldsymbol{Af}(\boldsymbol{TT}^{-1})+\boldsymbol{e} \\ = \boldsymbol{A}^*\boldsymbol{f}^*+\boldsymbol{e} \]
この\(\boldsymbol{A^*}\)と\(\boldsymbol{f^*}\)もまた2因子モデルの解である。そのため、座標軸の変換についての不定性がうかがえる。因子分析の実行においては、この特徴を逆手にとり、解釈が容易になるよう(単純構造化した)軸を回転させることが可能になる。ここでいう単純構造とは各変数が1つの因子だけから強い影響を受け、他の因子からの影響が0に近くなるように見える構造を意味している。
軸の回転の方法としては主に、直交回転と斜交回転という2つのアプローチが存在する。直交回転とは、因子負荷量行列に直交行列をかけた解のことである。この方法では、因子間に相関がないことを仮定している。直交回転法代表例がバリマックス回転である。一方で斜交回転は、直交ではない回転を表しており、因子間の相関を認める方法である。斜交回転法の代表例はプロマックス回転である。図11.4 は、川端ほか(2019 p.180)を参照した因子軸の回転について直感的に示した概要図である。回転なしの図では、すべての観測変数が \(f2\) に同じような負荷を持っていることがうかがえる。一方で、直交回転では、直交である条件は守ったままではあるが、\(1\sim 4\)はf1に高いがf2には低い値を取っていることがうかがえる。さらに斜交回転においては、軸の角度を自由に取ることができ、より単純構造化されていることがうかがえる。
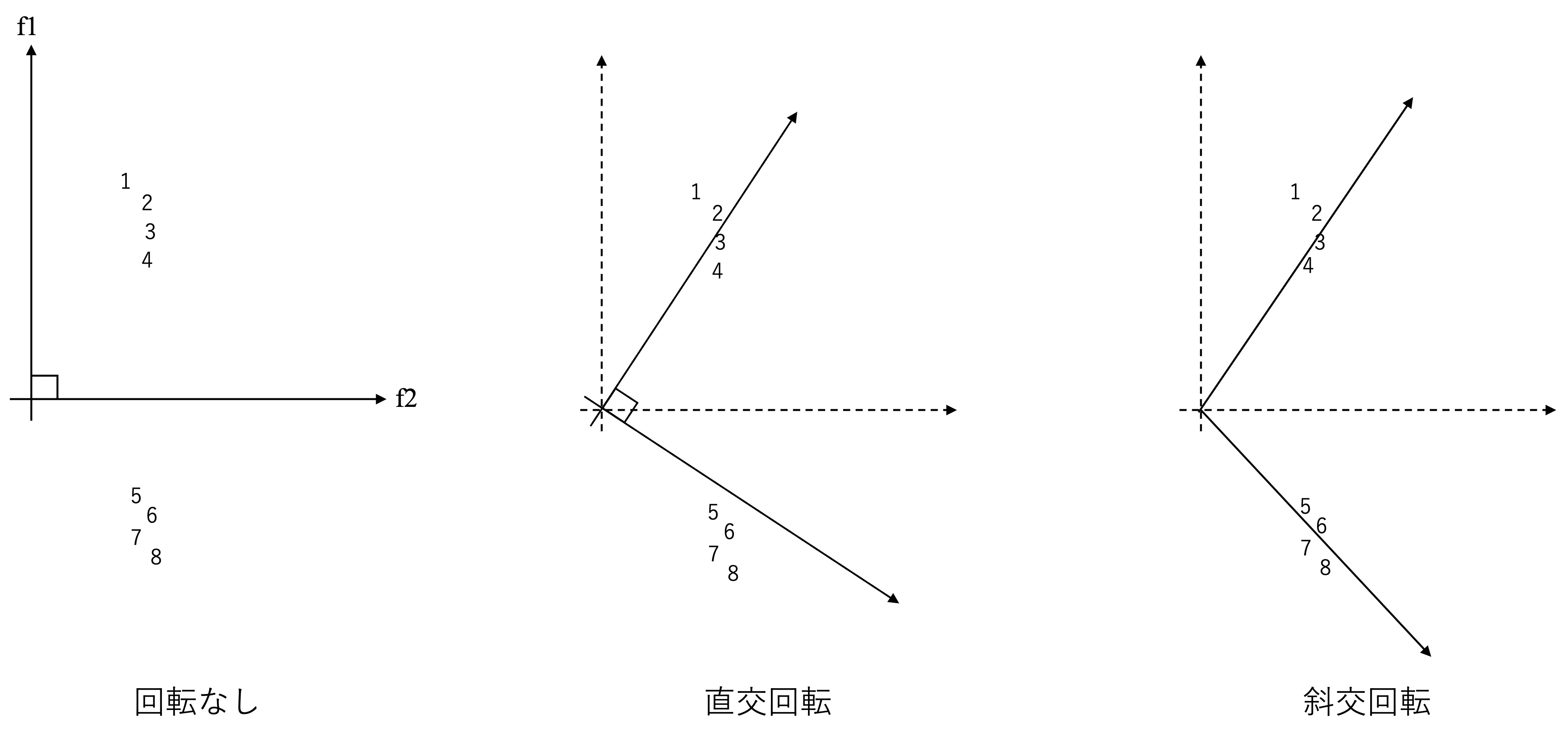
Figure 11.4: 因子軸の回転概要
因子分析では、モデルで採用する因子の数を自由に決定する事ができる。基本的には、より少ない因子数で全体を説明できることが好ましいのだが、説明力があり有力な因子は残すことも好ましい。ここでも、10 章での説明と同様、効率性と有効性のバランスを探ることになる。以下では、因子数を決めるために用いられている基準をいくつか紹介する。
第1に、各因子の固有値(eigen value)に基づく基準である。この基準では、各因子の確認し、1を越えていない因子についてはモデルに含めないと判断する。因子負荷量の行列は、データの相関行列を固有ベクトルと固有値(を持つ行列)にそれぞれ分解することで計算されている(分寺、2022)。この時計算される各因子の固有値はその因子の寄与率にも対応しており、固有値が1ということは、(直感的には)観測変数1項目分の分散を説明していると解釈することも可能である。そのため、固有値が1以上の因子のみをモデルに用いるという方法が慣習的に広く用いられている。しかしながら、この基準に対する批判も存在していることに注意が必要である。
第2の因子数判断基準にスクリープロットの活用がある。これは、因子数を横軸にとり、それに対応する固有値を縦にプロットしたものである。図11.5 はスクリープロットの例である。スクリープロットでは、固有値そのものに加え、因子数を増やすことによる固有値の変化量(傾き)の変化にも着目する。例えば図11.5 については、因子数が2から3への変化では傾きが急であるが、3以上になった点からプロットの傾きが緩やかになっている。この場合、3因子目は説明力が低く、それ以降の因子についても説明力が高くない事が伺える。そのため、11.5 の結果では、2因子モデルを採用することが有力となる。
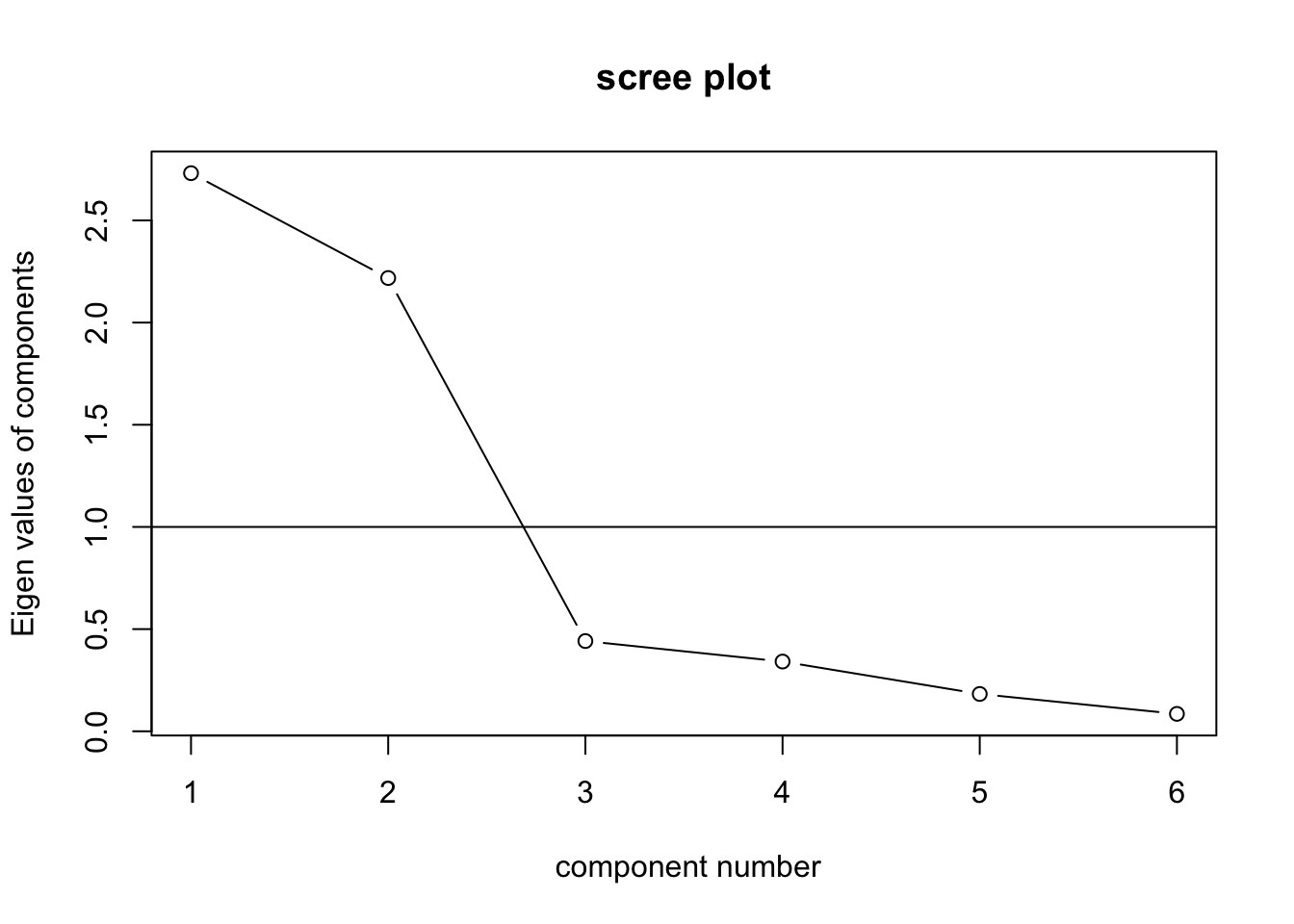
Figure 11.5: スクリープロット
固有値とスクリープロットによる因子数の決定は伝統的に広く用いられている基準であるが、この他にも、乱数を用いて計算された固有値との比較(平行分析)などがあるので、関心がある人はぜひ学習してみてほしい。
11.2.3 因子スコア
因子分析ではその結果に基づき、各個体が因子に対してどれだけの特性値を持っているのか、因子の得点を割り振ることができる。このように割り振られた因子についての値を因子スコア(因子得点)という。これは、抽出された因子についての予測値として解釈でき、最も基本的なスコアの求め方は回帰推定法と呼ばれる計算方法である。この方法では、個人 \(i\) における因子 \(f\) に対して(簡単化のために1因子モデルを考える)\(J\) 個の観測変数と、係数 \(b\) を想定すると、因子スコアの理論モデルは以下のように示すことができる。
\[ f_i = b_1x_{i1}+ b_2x_{i2}+...+ b_Jx_{iJ}+u_{ij}\\ = \sum^J_{j = 1}b_{j}x_{ij} + u_{i} \] ただし、\(u_{i}\) は、誤差項である。この因子の予測値を \(\hat{f}_i\) とし、以下の \(G1\) を最小化するような \(b\) を求めるのが、回帰推定法である。
\[ G1 = \sum^n_{i = 1} \left(f_i-\hat{f}_i\right) \]
11.2.4 小括
本節では、因子分析の概要についての説明を行った。因子分析の概念的な理解のためには、観測できる変数の背後に潜在因子というものが存在することを想定する必要がある。しかしながら観察できない潜在因子を測定するためには、観測変数間の共分散を用いる。ある変数同士が似ているということは、その背後に共通する因子が存在し、その因子から影響を受けているのではないかと考えているわけである。分析の結果、複数の変数を一纏めに捉えることができる因子が発見された場合、事後的に、「それはどのような因子か」を解釈し、名前をつける。このように、データに基づく結果を事後的に解釈することで因子を発見しようとするアプローチを「探索的因子分析」という。次節では、Rを用いた因子分析の実行方法を紹介しながら、探索的因子分析の手順や結果の解釈について説明する。
詳細は、補足資料か南風原(2002)を参照。↩︎