9.5 (おまけ)分析結果のまとめ・出力上の工夫
これまで本書では、分析結果について、Rで出力されるものをそのまま示していた。しかしながら、Rでの出力結果をレポートや論文にベタ貼りすることは、可読性の低下につながるため好ましくない。論文やレポート執筆の際には、Rで出力された結果から表を作成することが必要になるのだが、Excelなどのスプレッドシートに一つ一つの値をコピー・アンド・ペースト(コピペ)して表を作成していく方法は、操作ミスによる間違いの可能性が高まることと、作業プロセスを記録できない上に、何より面倒くさい。そこで、分析結果を読みやすく見た目も良い表の形式で楽に出力してくれるコマンドをR上で実行するした。そのために用いるパッケージは色々あるが、本書では modelsummary パッケージを 紹介する。以下のようにインストールして欲しい。
ここでは試しに、本節で実行した fit_intを msummary() 関数で出力する。Rstudio上でmsummary() を実行すると、結果がコンソールではなく、Viewerに表示される。
## `modelsummary` 2.0.0 now uses `tinytable` as its default table-drawing
## backend. Learn more at: https://vincentarelbundock.github.io/tinytable/
##
## Revert to `kableExtra` for one session:
##
## options(modelsummary_factory_default = 'kableExtra')
## options(modelsummary_factory_latex = 'kableExtra')
## options(modelsummary_factory_html = 'kableExtra')
##
## Silence this message forever:
##
## config_modelsummary(startup_message = FALSE)| (1) | |
|---|---|
| (Intercept) | 20326.588 |
| [20111.797, 20541.378] | |
| rd | -51.872 |
| [-52.433, -51.312] | |
| promotion | -191.431 |
| [-193.505, -189.358] | |
| rd × promotion | 0.498 |
| [0.493, 0.503] | |
| Num.Obs. | 221 |
| R2 | 0.994 |
| R2 Adj. | 0.993 |
| AIC | 1969.2 |
| BIC | 1986.2 |
| Log.Lik. | -979.617 |
| F | 11110.648 |
| RMSE | 20.36 |
上記のように引数をほぼ指定せずとも(statistic = 'conf.int' は信頼区間を出力する引数。デフォルトでは標準誤差)、このような表形式で結果を出力することができる。引数を用いることで、研究者に都合の良い表なるよう編集可能であることもこの関数の利点である。例えば、不必要な情報があれば、以下のように表から削除することもできる。
| (1) | |
|---|---|
| (Intercept) | 20326.588 |
| (108.978) | |
| rd | -51.872 |
| (0.284) | |
| promotion | -191.431 |
| (1.052) | |
| rd × promotion | 0.498 |
| (0.003) | |
| Num.Obs. | 221 |
| R2 | 0.994 |
| R2 Adj. | 0.993 |
| F | 11110.648 |
また、msummary() は二つ以上のモデルを並べて表示させる場合にも便利である。複数の分析結果を list としてまとめ以下のように出力できる。ここでは、交差項を用いた回帰モデルにおける中心化のありなしを併記し比較可能にする。更に、表示される変数名も調整する。
var_nam <- c("rd" = "R&D", "promotion" = "Promotion", "rd:promotion" = "R&D * Promotion",
"rd_c" = "R&D_c", "promotion_c" = "Promotion_c", "rd_c:promotion_c" = "R&D_c * Promotion_c",
"(Intercept)" = "定数項")
Int <- list()
Int[["Without centering"]] <- fit_int
Int[["With centering"]] <- fit_int_c
msummary(Int,
coef_map = var_nam,
title = "Comparing Interaction Models",
notes = "Values in [ ] show 95% confidence intervals",
stars = TRUE,
statistic = 'conf.int', conf_level = .95,
gof_omit = "Log.Lik.|AIC|BIC|RMSE")| Without centering | With centering | |
|---|---|---|
| + p < 0.1, * p < 0.05, ** p < 0.01, *** p < 0.001 | ||
| Values in [ ] show 95% confidence intervals | ||
| R&D | -51.872*** | |
| [-52.433, -51.312] | ||
| Promotion | -191.431*** | |
| [-193.505, -189.358] | ||
| R&D * Promotion | 0.498*** | |
| [0.493, 0.503] | ||
| R&D_c | -0.918*** | |
| [-0.941, -0.894] | ||
| Promotion_c | 0.690*** | |
| [0.612, 0.769] | ||
| R&D_c * Promotion_c | 0.498*** | |
| [0.493, 0.503] | ||
| 定数項 | 20326.588*** | 382.278*** |
| [20111.797, 20541.378] | [379.293, 385.263] | |
| Num.Obs. | 221 | 221 |
| R2 | 0.994 | 0.994 |
| R2 Adj. | 0.993 | 0.993 |
| F | 11110.648 | 11110.648 |
対外的に分析結果を共有する場合には、このような分析結果をViewer上ではなく、文書ファイル等に貼り付けたいと考えることも多いだろう。msummary() 関数では、引数を変更することで、出力形式を変更することも可能である。そのうえで、本書が最もおすすめする方法が、Latex形式での表の出力と、それを用いたLatexによる文書作成である。
Latex(ラテック or レイテック)は、ソースファイルにコマンドと文章を記載していきながらpdfを出力することで文書を作成するためのツールである。Latexは、数式や表の入力が簡単であり、出力結果もきれいであることや、文書フォーマットについて細かく気にせず文書を作成できるという利点がある。そのため、定量的な分析を伴う文書を作成するのに適したツールである。逆に短所としては、ソースコードの入力や、コンピュータ内へのLatex用環境構築に関する手間がかかるという点が挙げられる。しかし近年では、ウェブブラウザ上でLatexを動かせる “Overleaf” というサービスも普及し、環境構築による問題は解決されている。本書では、LatexやOverleafの詳細や設定方法については割愛するが、基本的にはOverleafの活用をおすすめするので、以下のリンクを参照して欲しい(https://dreamer-uma.com/overleaf/)。特に、卒業論文や修士論文に取り組む学生にとって、Overleafによってウェブ上にファイルを保管できることは非常に重要な利点となるだろう(毎年少なくない学生が論文のファイル保管ミスやノートPCの故障などのトラブルに見舞われるのを観察している)。
先程の交差項比較の表について、output = "latex" と引数を設定することで、出力形式を変更する。
msummary(Int,
title = "Comparing Interaction Models",
notes = "Values in [ ] show 95% confidence intervals",
stars = TRUE,
statistic = 'conf.int', conf_level = .95,
gof_omit = "Log.Lik.|AIC|BIC|RMSE", output= "latex")| Without centering | With centering | |
|---|---|---|
| + p < 0.1, * p < 0.05, ** p < 0.01, *** p < 0.001 | ||
| Values in [ ] show 95\% confidence intervals | ||
| (Intercept) | \num{20326.588}*** | \num{382.278}*** |
| [\num{20111.797}, \num{20541.378}] | [\num{379.293}, \num{385.263}] | |
| rd | \num{-51.872}*** | |
| [\num{-52.433}, \num{-51.312}] | ||
| promotion | \num{-191.431}*** | |
| [\num{-193.505}, \num{-189.358}] | ||
| rd × promotion | \num{0.498}*** | |
| [\num{0.493}, \num{0.503}] | ||
| rd\_c | \num{-0.918}*** | |
| [\num{-0.941}, \num{-0.894}] | ||
| promotion\_c | \num{0.690}*** | |
| [\num{0.612}, \num{0.769}] | ||
| rd\_c × promotion\_c | \num{0.498}*** | |
| [\num{0.493}, \num{0.503}] | ||
| Num.Obs. | \num{221} | \num{221} |
| R2 | \num{0.994} | \num{0.994} |
| R2 Adj. | \num{0.993} | \num{0.993} |
| F | \num{11110.648} | \num{11110.648} |
これにより出力される結果のうち、\begin{table} から \end{table} までのコード内容をそのままlatexにコピペし、コンパイル(文書出力)をすれば、以下のような表が出力される15。

いくらLatexが便利だと言っても、マーケティング分野においてはマイクロソフトWordによって文書を作成している教員や研究者も多い。そのため、指導教官や共同研究者との兼ね合いでLatexやOverleafを使えないという場合もある。そのため、もしどうしてもスプレッド形式で表を作成・編集したいと考えるのであれば、Googleスプレッドシートの拡張機能を利用するのが良いだろう。Google スプレッドシートに対応した “Spread-Latex”(https://workspace.google.com/marketplace/app/spreadlatex/218144906748) というアドオンによって、Latexコードで記載された表のソースコードをスプレッドシートに変換することができる。この拡張機能を利用すれば、ウェブブラウザで開いたGoogle スプレッドシート上にmsummary() によって出力された Latex コードを貼り付け、いくつかのクリック操作をするだけで、Latexコードからスプレッドシート型の表に変換できる。その後、少しの微調整(消えていないコードの削除など)を行うと、以下のような表を得る。
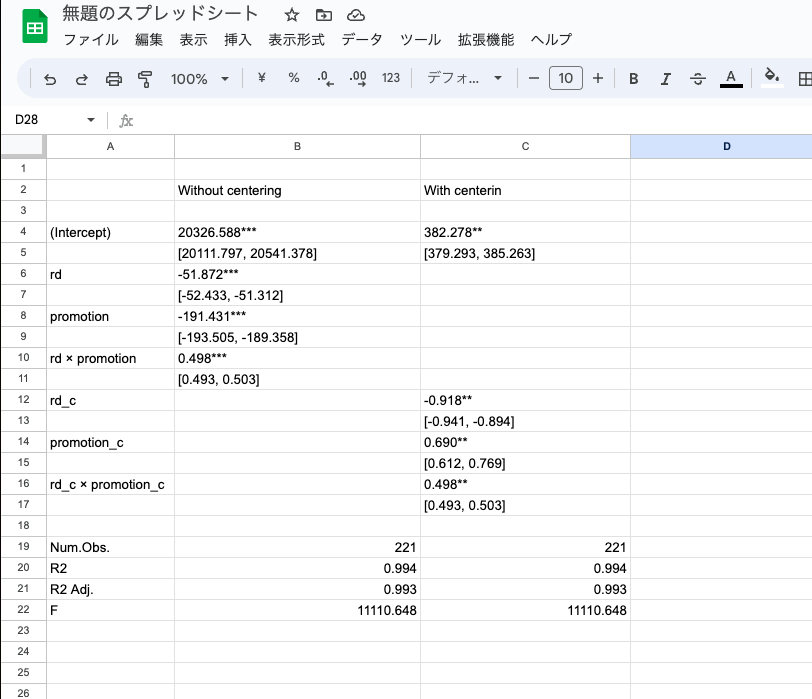
もしExcelで作業を行いたい場合には、このGoogleスプレッドシートに変換された表をExcelにコピペすれば良い。しかしながら、2023年現在ではこのアドオンの更新は続いているが、今後デベロッパーがどのように対応するかは不明であるため、これはあくまで一時的な対応策にとどめておくことが賢明かもしれない。
以上のように、既存のパッケージやサービスを用いることで、少ない労力で分析結果を表にまとめ、出力することが可能になる。ここで紹介した以外にも有力なパッケージがあるので、関心のある人は色々と調べて、自分にあったやり方を探してみて欲しい。
なお、Latexにおいては % 記号によってコメントアウトされるため、ソースコード内にある場合には、バックスラッシュを用いる調整が必要になる。↩︎