5.4 (おまけ) Wide型とLong型データセット
インターネットを通じて、とても都合の良いかつ信頼できるデータセットが入手できたとしても、それが分析のために望ましい形で保存されているとは限らない。特に、横長(wide)と縦長(long)データが存在し、それらのデータの型の違いには注意が必要である。我々人間がデータを眺め、解釈を与える場合にはwide型データのほうが扱いやすいのだが、コンピュータやソフトウェアがデータを分析する際には、long型のほうが好ましい。例えば、下図は4店舗のある年の6月から10月までの売上情報(単位:千円)を示したデータセットである。これは、複数サンプル-複数時点という構造のデータだが、各時点の観測値が横に並んでおり、wide型データだといえる。
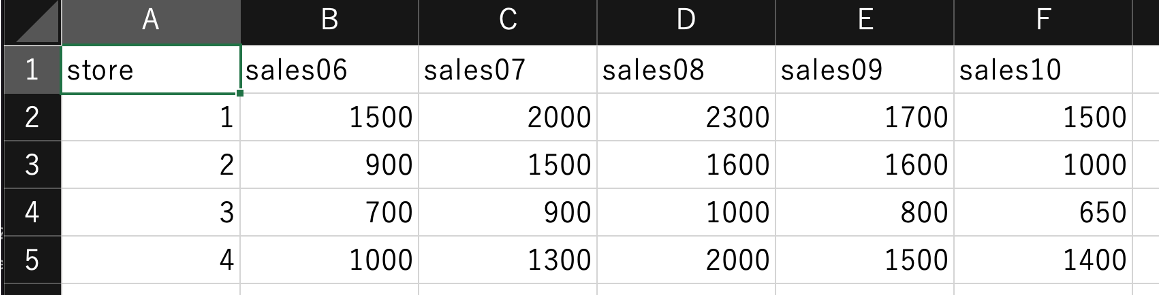
手元にあるWide型データをLong型に変換したい場合の対応策として、ここでは tidyverseに含まれているtidyrのgather()関数を用いる方法を紹介する。この関数の利用方法を実演するためにManabaにアップされている sales_wide.csv をダウンロードし、プロジェクト内のdataディレクトリに移して欲しい。データを読み込むと、以下のようにデータ構造を確認することができる。
## Rows: 4 Columns: 6
## ── Column specification ───────────────────────────────────────────────────────────
## Delimiter: ","
## dbl (6): store, sales06, sales07, sales08, sales09, sales10
##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.## # A tibble: 4 × 6
## store sales06 sales07 sales08 sales09 sales10
## <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 1 1500 2000 2300 1700 1500
## 2 2 900 1500 1600 1600 1000
## 3 3 700 900 1000 800 650
## 4 4 1000 1300 2000 1500 1400ここで用いる gather()関数は、以下の引数を指定する: - data: 変換元のデータ - key: 変数を1列にまとめたあと、元の列を区別するための列につける名前 - value: 変数を1列にまとめたあと、値が入る列につける名前 - どの範囲を一列にまとめるかの範囲指定
その上で、さきほどのsalesデータをLong型に変換するために、以下のようなコマンドを利用する。
sales_long<- gather(data = sales_wide, key = "month",
value = "sales", starts_with("sales"))
sales_long## # A tibble: 20 × 3
## store month sales
## <dbl> <chr> <dbl>
## 1 1 sales06 1500
## 2 2 sales06 900
## 3 3 sales06 700
## 4 4 sales06 1000
## 5 1 sales07 2000
## 6 2 sales07 1500
## 7 3 sales07 900
## 8 4 sales07 1300
## 9 1 sales08 2300
## 10 2 sales08 1600
## 11 3 sales08 1000
## 12 4 sales08 2000
## 13 1 sales09 1700
## 14 2 sales09 1600
## 15 3 sales09 800
## 16 4 sales09 1500
## 17 1 sales10 1500
## 18 2 sales10 1000
## 19 3 sales10 650
## 20 4 sales10 1400編集された縦長データは上記の通り示されるが、その中身を見ると、monthの列にsales06などの情報が記載されており、好ましくない。この問題は、元のデータにおける変数名に該当する情報を新しいkey列の値に使うというgather関数の仕様に影響するものである。この問題に対しては、パイプ演算子を使ってgatherの実行前に、列名を年だけの形に変更することで対応可能である。以下が、修正版のコードであり、出力結果より、先述の問題点が解決されたことが確認できる。ただし、gather関数の実行において、下記コード内では範囲の引数の指定についても修正されていることに注意が必要である。
sales_long <- sales_wide %>%
rename(`06` = sales06,
`07` = sales07,
`08` = sales08,
`09` = sales09,
`10` = sales10) %>%
gather(key = "month",value = "sales",
`06`:`10`) %>%
arrange(store)
sales_long## # A tibble: 20 × 3
## store month sales
## <dbl> <chr> <dbl>
## 1 1 06 1500
## 2 1 07 2000
## 3 1 08 2300
## 4 1 09 1700
## 5 1 10 1500
## 6 2 06 900
## 7 2 07 1500
## 8 2 08 1600
## 9 2 09 1600
## 10 2 10 1000
## 11 3 06 700
## 12 3 07 900
## 13 3 08 1000
## 14 3 09 800
## 15 3 10 650
## 16 4 06 1000
## 17 4 07 1300
## 18 4 08 2000
## 19 4 09 1500
## 20 4 10 1400一方で、Long型データからWide型データへ変換するためには、tidyrのspread()を用いることが多い。spread() では、主に以下の引数を用いる。
- data: 変換元のデータ
- key: 変数を複数列にわけるとき、列を区別するための変数
- value: 複数列に分ける値
例えば、以下のコードで先程の sales_long データをwide型に変換することができる。
wide_test <- sales_long %>%
spread(key = "month", value = "sales") %>%
rename(sales06 = `06`,
sales07 = `07`,
sales08 = `08`,
sales09 = `09`,
sales10 = `10`)
wide_test## # A tibble: 4 × 6
## store sales06 sales07 sales08 sales09 sales10
## <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 1 1500 2000 2300 1700 1500
## 2 2 900 1500 1600 1600 1000
## 3 3 700 900 1000 800 650
## 4 4 1000 1300 2000 1500 1400