5.3 統計的検定を用いない顧客分析
5.3.1 データの構造変化とソート
顧客の購買データを用いて、(統計的な分析を要さず)重要顧客や顧客層を発見することが、小売企業を中心に行われている。ここでは基本的に、ID-POSデータを用いたデータベースの正規化と集計2焦点を合わせる。特に、顧客個人に関する情報を用いながら企業や店舗にとって重要な顧客を特定し、その顧客との関係性を深めた場合を考える。店舗の運営効率から考えると、単に来店客数を増やすだけでなく、より頻繁に、より高額の買い物をする顧客を特定し、その人(達)の購買を促進することが効果的になる。言い換えると、企業や店舗は、ロイヤルカスタマーを特定し、その顧客との関係性を構築したいと考えるのである。そのためにはまず、ロイヤルカスタマーを特定する作業が必要になる。そこで本節では、データから企業にとって価値のある顧客を発見する方法について、データの前処理技術を応用する形で紹介する。
本節では簡単に、単純なデータハンドリングから顧客インサイトを得る方法を考える。特に、データ処理とソーティング(順番の入れ替え)を用いる方法を用いる。本節ではID-POSデータを用いた分析として、デシル分析とRFM分析を紹介する。デシル分析は、支出額をもとに上位から顧客を並べ替え、その順番に基づき顧客を10分割することで、上位の支出額を担うランクに属する顧客を特定する。なお、他の指標で同様の分析を実行することも可能だが、一般的には支出額を用いることが多い。例えば、月当たり5000人の顧客がいるとすると、500人ずつのグループに分け、購買額の大きい順にデシル1〜10 (10〜1の場合もある) とする形でランク分けする方法がこれにあたる。このとき、各顧客の情報がポイントカードやアプリで紐付いているのであれば、最も購買額の多いグループの特徴を整理することで、現在購入額の高い顧客がどんな特徴を持つのか理解できる。
一方、RFM(Recency, Frequency, Monetary)分析は、取引情報から、最近いつ買ったか、どれだけの頻度で買い物するか、どれだけ支出しているかといった情報を総合的に勘案し、どの顧客が最重要かを特定する方法である。これらの指標は、ロイヤルティや再購買確率が高い顧客を判別するのに役立つ3つの指標である。例えば、最終購買日から時間が経っている顧客は離反しているかもしれないし、購買頻度や購買額が高いと、ロイヤルティが高い可能性が高い。また、クーポンや割引利用の有無の情報と紐付けることができれば、当該顧客がチェリーピッカーか否かも判断することができる。
ID-POSデータは、各顧客の会員IDについての情報はありながらも取引ベースで情報が整理されている。このようなデータに対して以下の手順を用いてデータを集計・ソーティングする。
- 顧客IDごとに、各取引情報を集計する。
- 顧客ID情報についてまとめたデータベースにおける順番をソートし、重要顧客を識別する。
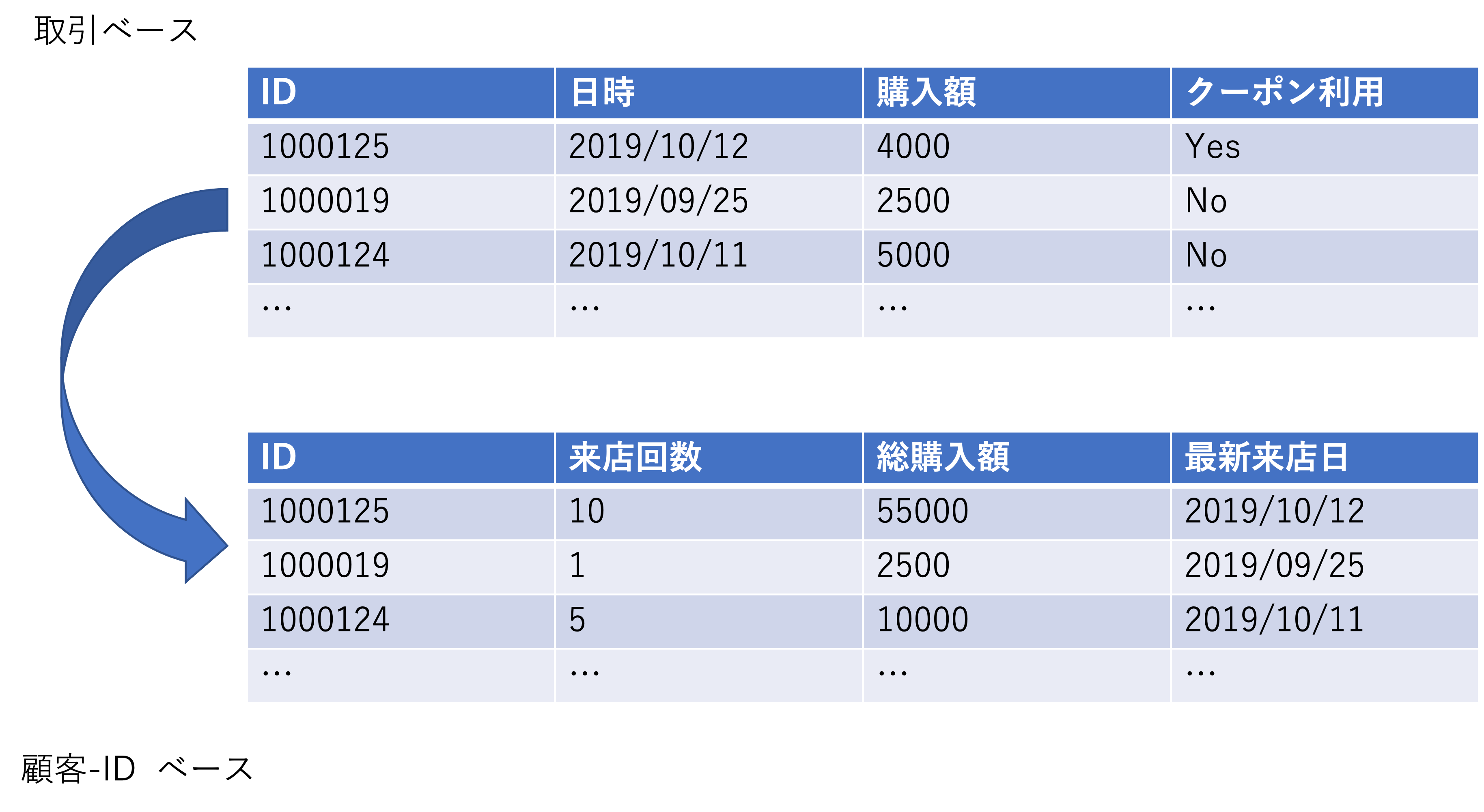
このようなデータの集計は、データ構造を取引ベースから顧客IDベースに変換することを可能にする。下図は、取引ベースのID-POSデータを、集計作業によって顧客IDベースのデータ構造に変換するイメージを示したものである。ID-POSデータは、顧客ID情報が含まれていながらも、データの行(観測)は各取引を示している。そのため、仮に同じIDの顧客がデータ収集期間に複数回取引を行っている場合、同じIDを含む観測がいくつも見られることになる。一方で下部の顧客IDベースのデータは、ID-POSデータを顧客ID情報によって集計したものであり、一定期間中に特定のIDを持つ顧客がどのような購買行動を示していたかを捉えたデータである。そのため、データの行は各顧客IDを示している。本節では、まずはじめにこのようなデータ構造の変換について説明する。
ここでは、先程利用した idpos データを用いて作業を進める。改めて、当該データを以下のコマンドで確認する。
## # A tibble: 6 × 4
## id date spent coupon
## <dbl> <chr> <dbl> <dbl>
## 1 12 2019/9/25 14326 1
## 2 32 2019/9/10 10232 1
## 3 30 2019/9/9 6881 1
## 4 29 2019/9/4 6365 0
## 5 46 2019/9/10 7595 1
## 6 44 2019/9/14 7858 0ここで、date変数を用いて直近で何日前の来店かを示す変数を作成する。このデータは、2019年09月01日 から 2019年10月01日までの一ヶ月間、とある店舗で記録された取引データであると仮定し作成されている。そのため、データ収集終了最新時点(2019-10-2)と来店日時の差を表す変数を作成する (ここでの処理にエラーが出る場合は、idpos$date <- as.Date(idpos$date) というコマンドを事前に試してから変数の定義を行ってほしい)。head関数により出力された結果によって新たな変数(datediff)が追加されたことがわかる。
## # A tibble: 6 × 5
## id date spent coupon datediff
## <dbl> <chr> <dbl> <dbl> <dbl>
## 1 12 2019/9/25 14326 1 7
## 2 32 2019/9/10 10232 1 22
## 3 30 2019/9/9 6881 1 23
## 4 29 2019/9/4 6365 0 28
## 5 46 2019/9/10 7595 1 22
## 6 44 2019/9/14 7858 0 18続いて、パイプ演算子を使ったデータ処理によって顧客IDベースの形へ集計する。ここでは特に、group_by() という関数を使い、顧客id (今回は性別情報も残したいので gender も加えている)をグループ化の基準と指定する形で集計を行う。また、CRM分析で使う変数のために、idレベルでの集計という形で以下の変数を作成する。そして、以下の変数を用いて集計した新たなデータセットを “idpos_cust” として定義する。
- frequency:各idの出現頻度をn()でカウントする
- monetary:spentの合計をsum()で計算する
- cherry (picker):クーポンの利用回数の合計をsum()で計算する
- recency:datediffの最小値をmin()で求め、直近でいつ来たかを判別
idpos_cust <- idpos %>%
group_by(id) %>%
summarize(frequency = n(),
monetary = sum(spent),
cherry = sum(coupon),
recency = min(datediff)
)
head(idpos_cust)## # A tibble: 6 × 5
## id frequency monetary cherry recency
## <dbl> <int> <dbl> <dbl> <dbl>
## 1 1 21 173314 8 1
## 2 2 20 157976 13 2
## 3 3 21 134673 5 1
## 4 4 19 154416 10 4
## 5 5 20 177156 11 3
## 6 6 19 151853 11 3上記の操作によって、元々のidposデータから、顧客ベースのデータ構造(idpos_cust)に変換できたはずである。しかしこれだけでは、まだ我々は誰が重要顧客か特定できない。そのため、次に我々はデータの並べかえを行う。具体的には、支出額が高い順に並び替えたあとに上位20人の顧客を表示する。
idpos_cust_m <- idpos_cust %>%
arrange(desc(monetary))
##Customers in the top 20 (Monetary)
idpos_cust_m[1:20,]## # A tibble: 20 × 5
## id frequency monetary cherry recency
## <dbl> <int> <dbl> <dbl> <dbl>
## 1 15 31 305665 13 1
## 2 35 30 262181 13 1
## 3 31 31 254804 19 3
## 4 33 29 251352 14 2
## 5 22 24 214150 9 4
## 6 20 21 199197 11 2
## 7 18 24 196686 13 3
## 8 49 24 196143 12 4
## 9 9 24 195788 14 1
## 10 12 25 194860 15 1
## 11 42 21 193582 5 1
## 12 30 26 190687 17 2
## 13 36 20 189937 13 6
## 14 14 21 188600 14 1
## 15 26 22 184657 10 2
## 16 32 20 184276 12 1
## 17 17 19 181947 13 1
## 18 44 23 181397 12 1
## 19 34 20 179533 8 2
## 20 37 21 179169 11 25.3.2 データ結合
ここまでの結果からは購買額の高い顧客IDを特定することができた。しかしながら、これらの顧客がどのような特徴を持っているのかについては推察できない。そのため、別で管理されていた顧客情報を捉えたデータセットと結合することでこれらの顧客についての属性を把握する。 以下では、今回使用する顧客情報データセットを読み込み、その概要を示している。このデータセットには、3000人分の会員登録済み顧客情報が蓄積されており、以下の変数を含む:
- id: 顧客ID
- gender: 性別
- age: 年齢
- famsize: 世帯人数
## spc_tbl_ [3,000 × 4] (S3: spec_tbl_df/tbl_df/tbl/data.frame)
## $ id : num [1:3000] 1 2 3 4 5 6 7 8 9 10 ...
## $ gender : chr [1:3000] "female" "male" "female" "female" ...
## $ age : num [1:3000] 51 38 41 24 48 46 36 30 26 57 ...
## $ famsize: num [1:3000] 2 2 1 1 5 1 1 1 3 5 ...
## - attr(*, "spec")=
## .. cols(
## .. id = col_double(),
## .. gender = col_character(),
## .. age = col_double(),
## .. famsize = col_double()
## .. )
## - attr(*, "problems")=<externalptr>ここで、顧客データと購買データを left_join() を用いて、idpos_cust をメインとする形で id によって結合する。left_join() は左側に指定したデータフレームに存在知するキーの行を返す形でデータの結合を行う。言い換えると、左側のデータセットに存在する行(観測)はすべて残され、そこに新たな変数を加える形でデータフレーム間の結合を行う。
## # A tibble: 6 × 8
## id frequency monetary cherry recency gender age famsize
## <dbl> <int> <dbl> <dbl> <dbl> <chr> <dbl> <dbl>
## 1 1 21 173314 8 1 female 51 2
## 2 2 20 157976 13 2 male 38 2
## 3 3 21 134673 5 1 female 41 1
## 4 4 19 154416 10 4 female 24 1
## 5 5 20 177156 11 3 female 48 5
## 6 6 19 151853 11 3 female 46 1上記の通り、顧客ベースの取引情報に、各顧客の属性情報が追加された事がわかる。これを利用し、以下のように上位20顧客の性別比率を以下のように確認する。これによって、主要顧客に占める性別比率が確認できる。
idpos_cust_m <- idpos_cust %>%
arrange(desc(monetary))
#gender ratio in the top 20
table(idpos_cust_m[1:20,]$gender)##
## female male
## 16 4続いては先述のデシル分析を実行する。具体的には、idpos_custに対し、cut()関数を使うことで、monetaryの大きさに基づきサンプルを10等分し、新たに “decile_rank” という変数(列)をデータに追加し、その新たなデータセットを “idpos_cust_m”と定義する。なお、次節にてこのデータを改めて使うため、データをprojectのdataディレクトリ内に保存しておいてほしい。
idpos_cust_m$decile_rank <-
cut(idpos_cust_m$monetary,
quantile(idpos_cust_m$monetary, (0:10)/10,na.rm=TRUE),
label=FALSE,include.lowest=TRUE)
head(idpos_cust_m)## # A tibble: 6 × 9
## id frequency monetary cherry recency gender age famsize decile_rank
## <dbl> <int> <dbl> <dbl> <dbl> <chr> <dbl> <dbl> <int>
## 1 15 31 305665 13 1 female 19 3 10
## 2 35 30 262181 13 1 female 22 3 10
## 3 31 31 254804 19 3 female 55 1 10
## 4 33 29 251352 14 2 male 54 5 10
## 5 22 24 214150 9 4 female 53 4 10
## 6 20 21 199197 11 2 female 50 1 10head()関数によって新たな変数の追加を確認したあとは、各デシルの店舗売上への貢献度を確認する。ここでは、decile_rankをグループ化の基準として設定し、summarize() によって集計する方法を用いる。その後、各デシルの売上比率を計算し、高い順に並び替える。集計・分析の結果は、上位20%の顧客で、ID-POSに計上されている売上の57%を締めていることを示した。
decile <- idpos_cust_m %>%
group_by(decile_rank) %>%
summarize(freq = n(),
monetary = sum(monetary))
total <- sum(decile$monetary)
decile2 <- decile %>%
mutate(percent = monetary/total*100) %>%
arrange(desc(decile_rank))
decile2## # A tibble: 10 × 4
## decile_rank freq monetary percent
## <int> <int> <dbl> <dbl>
## 1 10 149 11141710 45.1
## 2 9 149 3042467 12.3
## 3 8 147 2220019 8.98
## 4 7 150 1976807 8.00
## 5 6 148 1687031 6.83
## 6 5 149 1466609 5.93
## 7 4 149 1213922 4.91
## 8 3 148 939338 3.80
## 9 2 149 670413 2.71
## 10 1 149 358988 1.45本節で示したように、高度な統計的分析を実行せずとも重要顧客を特定する事が可能になる。本節では特に、データの集計や処理技術を使った方法を紹介した。このような分析によって回答できる問いは「企業にとっての重要顧客は誰か」というものだろう。この問いは非常に興味深く実務的にも有意義なものであるが、以下の点に注意することが重要である。第一に、何をもって顧客の重要性を定義するかという問題である。本節では特にRFMなどの基準を用いて、観察可能な購買結果をもとに重要顧客を識別する方法を捉えた。しかしながら、例えば購買頻度と購買額では異なる側面を捉えており、どの指標を用いて分析するかによって(通常は)結果が異なる。そのため、研究者自身が「重要性」をどのように定義するのかを注意深く判断し、なおかつそれをレポートやプレゼンテーション内できちんと明示する必要がある。さらに、データでは捉えきれない側面は分析結果に反映されないという点についても注意が必要である。例えば日本には江戸時代から続く小売企業もいくつも存在する。仮に、そのような小売企業と、長期間代々取引を続けている顧客(一族や企業)がいたとして、さらにその顧客が分析による上位顧客に含まれなかったとする。その場合、この顧客を重要顧客でないと切り捨てて良いのでだろうか。災害、国家の統治体制の変化、戦争、などの激動を経てなお取引が続いている顧客は重要でないと言い切れるのだろうか。もちろん、このような顧客を重要でないと捉えることも、経営判断として間違ったものではない。しかしながら、少なくともデータを用いた分析結果を過信しすぎず、データによって何が捉えられており、何が捉えきれていないのかについて研究者・意思決定者のどちらも自覚的になることが必要になる。
第二に、分析を行うだけでマーケティング実務が完結するわけではないという点についても注意が必要である。「重要顧客を特定する」という研究課題の背後には、「CRMを実行して収益性を向上させる」という実務的課題が存在しているはずである。そのため、今回の発見物をもとに、マーケティング活動への示唆を与えていくことが重要になるのだが、誰が重要顧客か、という問いに答えるだけでは具体的な活動指針(アプリを通じた囲い込みや、訪問販売等)を与えるのは難しい。そのため、重要顧客のライフスタイルや価値観などの彼/彼女らの特徴に踏み込んだ調査を行うことも必要になるかもしれない。昨今のロイヤルティプログラム(ポイントシステム)では、モバイルアプリを通じて個人の様々な行動履歴が記録されたり、アンケートへの回答を促されたりすることがあるだろう。これらの情報とID-POSデータをうまく接合できれば、重要顧客を特定しつつ、それらの顧客に適したCRM方策を策定できるかもしれない。